Lin Yen-Chen, Pete Florence, Andy Zeng, Jonathan T. Barron, Yilun Du, Wei-Chiu Ma, Anthony Simeonov,
Alberto Rodriguez Garcia, Phillip Isola
Humans form mental images of 3D scenes to support counterfactual imagination, planning, and motor control. Our abilities to predict the appearance and affordance of the scene from previously unobserved viewpoints aid us in performing manipulation tasks (e.g., 6-DoF kitting) with a level of ease that is currently out of reach for existing robot learning frameworks. In this work, we aim to build artificial systems that can analogously plan actions on top of imagined images. To this end, we introduce Mental Imagery for Robotic Affordances (MIRA), an action reasoning framework that optimizes actions with novel-view synthesis and affordance prediction in the loop. Given a set of 2D RGB images, MIRA builds a consistent 3D scene representation, through which we synthesize novel orthographic views amenable to pixel-wise affordances prediction for action optimization. We illustrate how this optimization process enables us to generalize to unseen out-of-plane rotations for 6-DoF robotic manipulation tasks given a limited number of demonstrations, paving the way toward machines that autonomously learn to understand the world around them for planning actions.
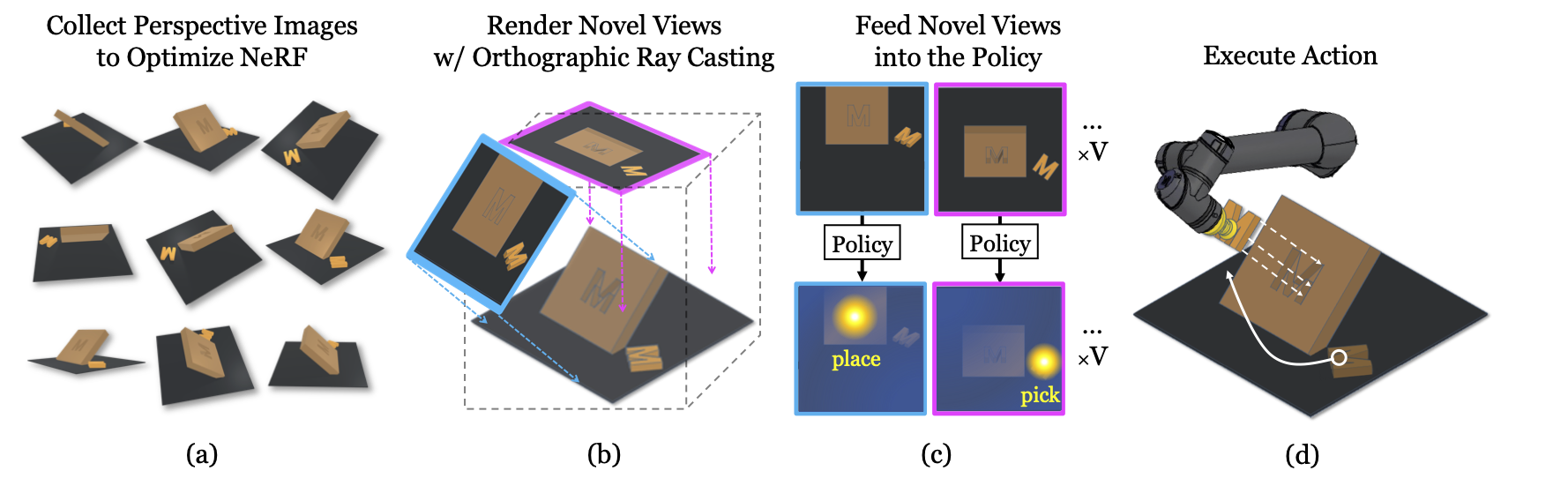
(a) Given a set of multi-view RGB images as input, we optimize a neural radiance field representation of the scene via volume rendering with perspective ray casting. (b) After the NeRF is optimized, we perform volume rendering with orthographic ray casting to render the scene from V viewpoints. (c) The rendered orthographic images are fed into the policy for predicting pixel-wise action-values that correlate with picking and placing success. (d) The pixel with the highest action-value is selected, and its estimated depth and associated view orientation are used to parameterize the robot’s motion primitive.