Lin Yen-Chen1,2, Pete Florence1,
Jonathan T. Barron1,
Alberto Rodriguez2, Phillip Isola2, Tsung-Yi Lin1
1Google, 2MIT
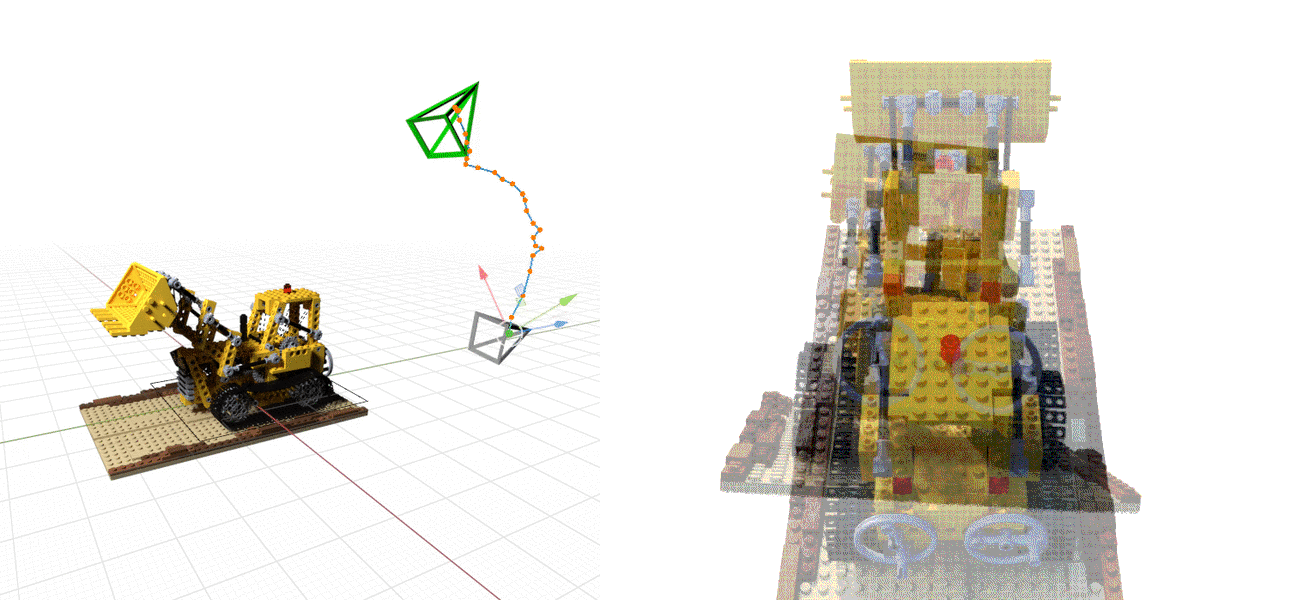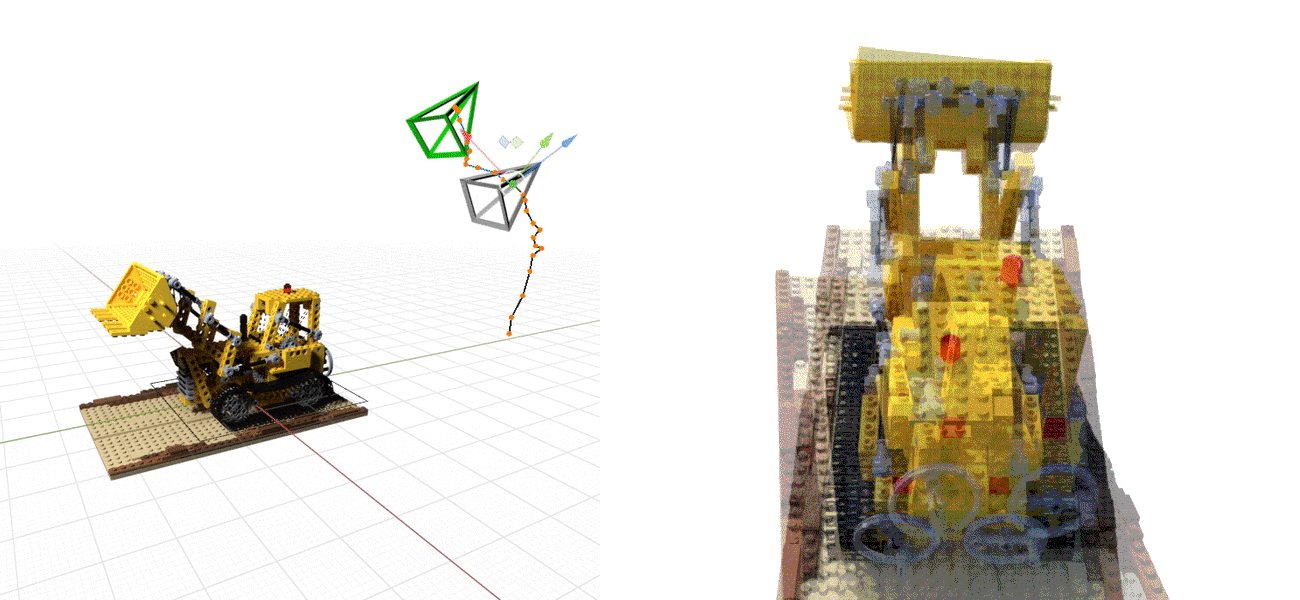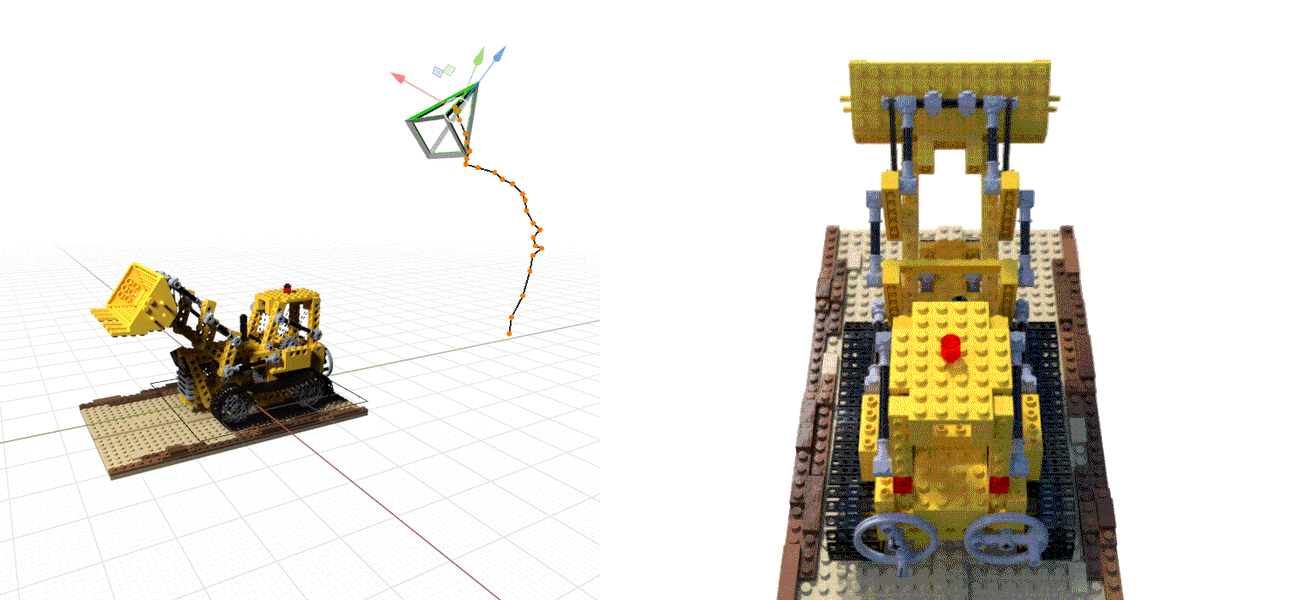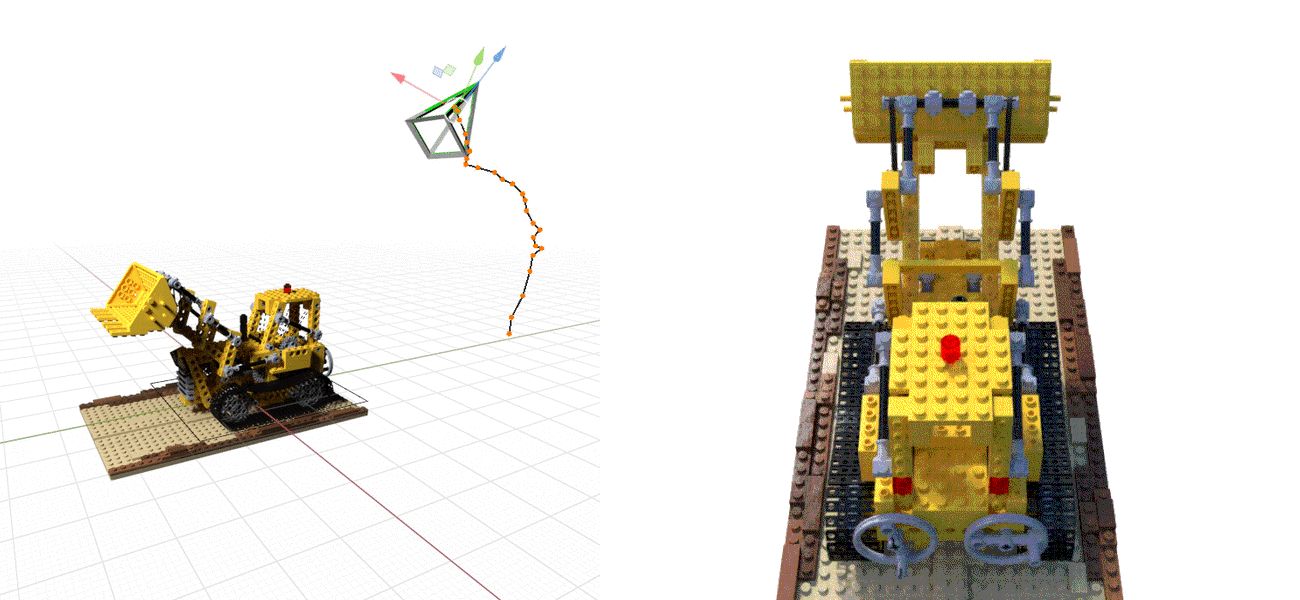
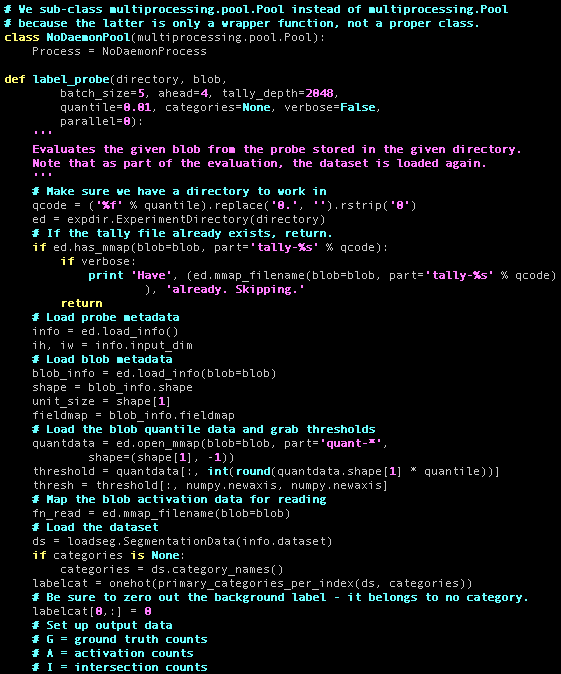
We explore how to perform pose estimation when the objects or scenes are represented as trained Neural Radiance Fields (NeRFs). Left: Gray camera represents the estimated poses during the optimization; Green camera represents the ground truth camera pose. Right: Overlay of the rendered and observed images at each optimization step.
We present iNeRF, a framework that performs pose estimation by “inverting” a trained Neural Radiance Field(NeRF). NeRFs have been shown to be remarkably effective for the task of view synthesis — synthesizing photorealisticnovel views of real-world scenes or objects. In this work, we investigate whether we can apply analysis-by-synthesis with NeRF for 6DoF pose estimation – given an image, find the translation and rotation of a camera relative to a 3Dmodel. Starting from an initial pose estimate, we use gradient descent to minimize the residual between pixels rendered from an already-trained NeRF and pixels in an observed image. In our experiments, we first study 1) how to sample rays during pose refinement for iNeRF to collect informative gradients and 2) how different batch sizes ofrays affect iNeRF on a synthetic dataset. We then show that for complex real-world scenes from the LLFF dataset, iNeRF can improve NeRF by estimating the camera poses of novel images and using these images as additional trainingdata for NeRF. Finally, we show iNeRF can be combinedwith feature-based pose initialization. The approach outperforms all other RGB-based methods relying on syntheticdata on LineMOD.
Pose tracking in real-world images without the need for mesh/CAD model. At each time step, iNeRF leverages a NeRF model inferred by pixelNeRF (Yu et al.) based on input frame at time t-1 to estimate the object's pose.


Pose estimation of object or camera. We show overlaid images of the rendered and observed images during the optimization of pose. These examples show that iNeRF is able to recover from large rotation and translation error in both synthetic and real setting.






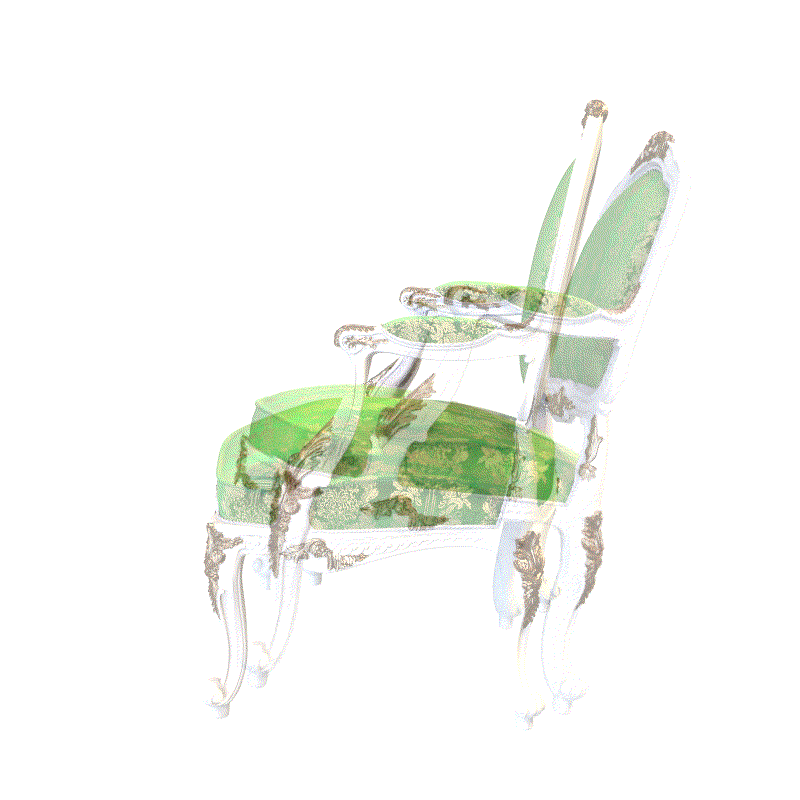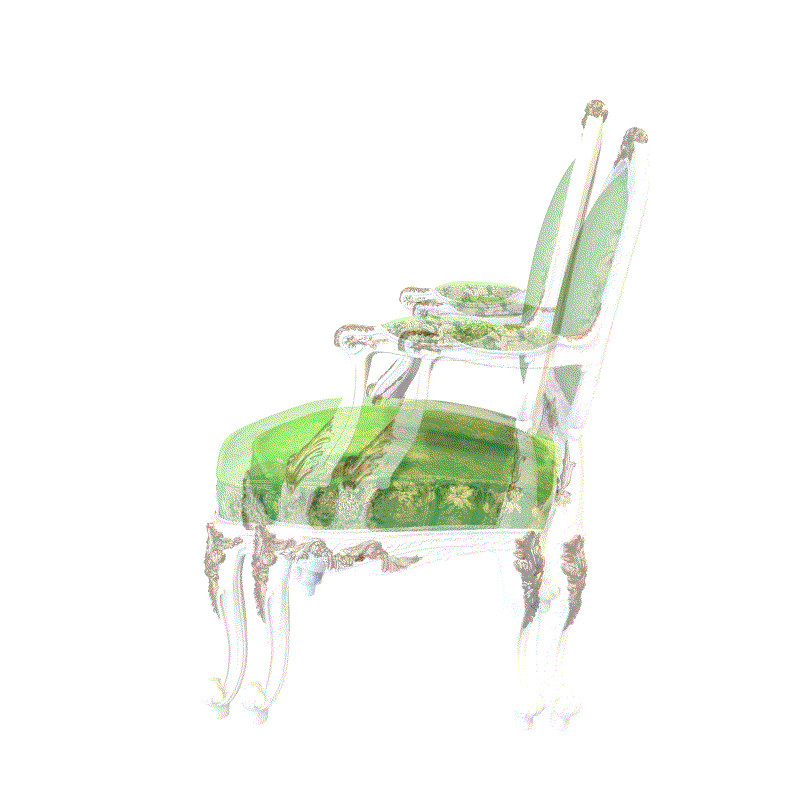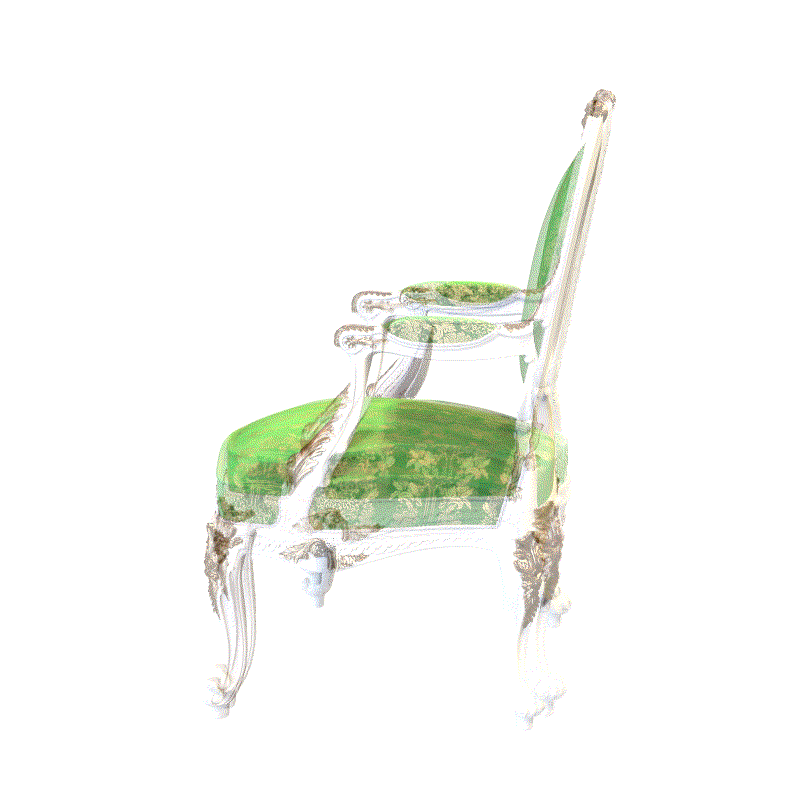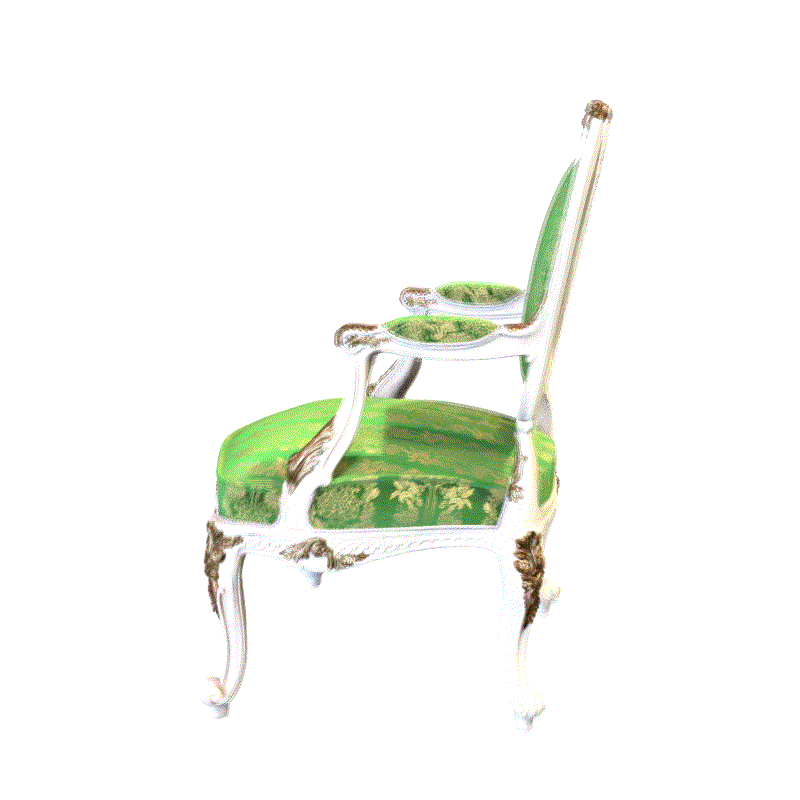
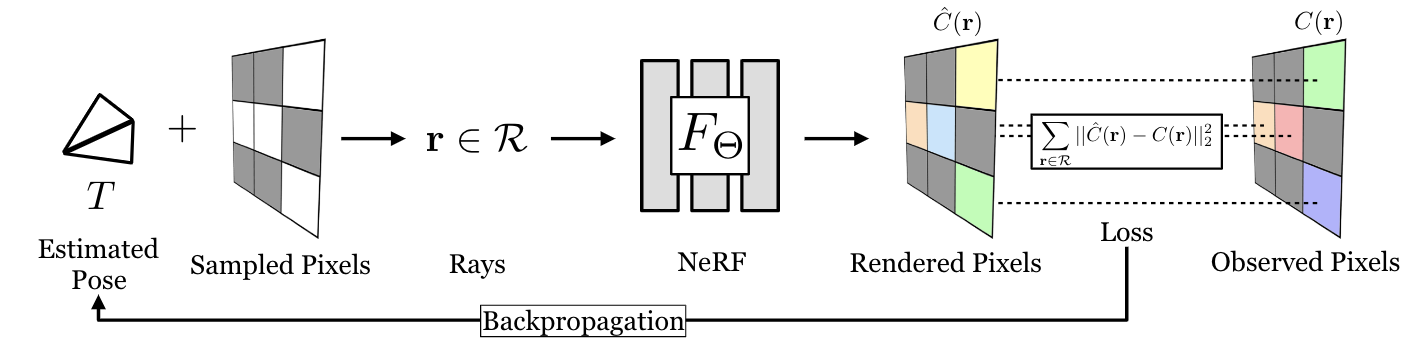
An overview of our pose estimation pipeline which inverts an optimized neural radiance field (NeRF). Given an initially estimated pose, we first decide which rays to emit. Sampled points along the ray and the corresponding viewing direction are fed into NeRF’s volume rendering procedure to output rendered pixels. Since the whole pipeline is differentiable, we can refine our estimated pose by minimizing the residual between the rendered and observed pixels.