Video Generation Models Explosion 2024
Video generation models exploded onto the scene in 2024, sparked by the release of Sora from OpenAI. This blog post is my way of keeping track of the progress of this fascinating field. I will review all the key techniques that are used in building state-of-the-art video generation models (1).
-
- A comprehensive review of all text-to-image/text-to-video models is beyond the scope of this blog post. I will focus on research that has been published, productionized, or open-sourced.
- All of the videos and images are reproduced from the cited projects and papers, and the copyright belongs to the authors or the organization that published their papers. Below I adapted key figures for each paper under the fair use clause of copyright law.
An amazing 1080p video generated by Sora.Sora is here! It's a diffusion transformer that can generate up to a minute of 1080p video with great coherence and quality. @_tim_brooks and I have been working on this at @openai for a year, and we're pumped about pursuing AGI by simulating everything! https://t.co/DzbyReLJEc pic.twitter.com/IFqfh8H6FW
— Bill Peebles (@billpeeb) February 15, 2024
Note
-
If you think the title looks familiar, it is a tribute to Frank Dellaert's NeRF Explosion 2020.
-
You will understand this blog post better if you are familiar with diffusion models. If not, I recommend reading Calvin Luo's tutorial first.
Many foundational designs of video generation models are derived from image generation models as an image is essentially a 1-frame video. Let's first explore the rationale behind these designs.
Prelude: Image Generation Models
SD1 (Rombach et al., 2022) introduces Latent Diffusion Models (LDMs), a framework that first encodes images from high-dimensional pixel space into a low-dimensional latent space using a pre-trained encoder \(\mathcal{E}\), then learn a diffusion model \(\epsilon_{\theta}\) based on U-Net in this compressed latent space. This framework is visualized below:
Figure 1. llustration of Latent Diffusion Models (LDM) framework.
By avoiding computation in the high-dimensional pixel space, LDMs dramatically reduce computational and memory requirements compared to pixel-space diffusion models. This innovation was crucial in democratizing access to powerful image generation models, enabling training and inference by more researchers and developers. To characterize how influential it is, a whole subreddit r/StableDiffusion is dedicated to it and its derivatives.
DiT (Peebles et al., 2023) uses the same LDM framework but it replaces the U-Net architecture with a Transformer that operates on latent patches. Through extensive experiments, DiT demonstrates that the U-Net's inductive bias is not crucial for diffusion model's generation quality. Additionally, the authors discover that injecting the denoising time step through Adaptive LayerNorm with zero initialization (AdaLN-Zero) is essential for transformer-based diffusion models to perform well. The detailed architecture and AdaLN-Zero design is shown below:
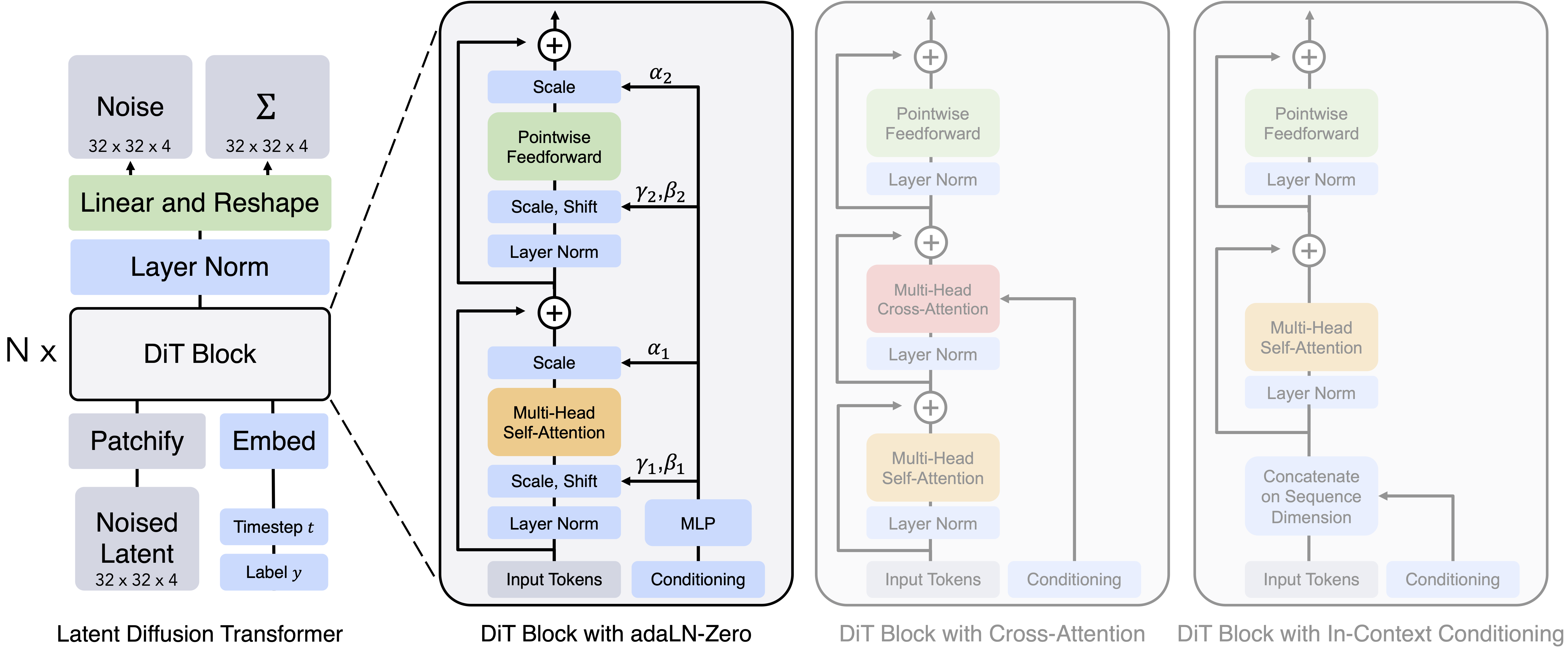
Figure 2. The Diffusion Transformer (DiT) architecture.
The transition from U-Net to Transformer is a crucial step as it later allows researchers to reuse scaling techniques from LLMs such as GPU parallelisms when training large video generation models.
DALL·E 3 (Betker et al., 2023) proposes using GPT to rewrite image captions, reducing noise in curated internet-scale text-image pairs for more effective training. This strategy causes the image generation models to naturally adapt to the distribution of long, highly-descriptive captions emitted by GPT. During inference, a "prompt rewriter" is used to convert user input into these highly descriptive prompts, enabling the model to better understand user intent and generate higher quality images.
Summary
- LDMs significantly reduce the computational cost of image generation models.
- For diffusion models, moving from U-Net to Transformer is a crucial step that allows researchers to reuse scaling techniques from LLMs.
- Long, high-quality, detailed captions improve the quality of image generation models as the mapping from text to image is more explicit and thus easier to learn.
Video Generation Models
With the strong results from image generation models, many researchers have tried to tackle video generation. Compared to modeling static images, modeling dynamic videos is harder due to the following challenges:
- Computational cost: Training and inference of video generation models are much more expensive than image generation models.
- Data availability: High-quality video data, especially paired with text descriptions, is much harder to collect at scale compared to images or text.
Some earlier attempts (circa 2022) are based on pixel-space diffusion models, e.g., Imagen-Video (Ho et al., 2022) and Make-A-Video (Singer et al., 2022). However, these methods are only able to generate relatively low-resolution and short videos. To alleviate the high computational cost for training with high-resolution videos, researchers explored building LDM-based video generation models.
Video LDM (Blattmann et al., 2023) fine-tunes pre-trained image LDMs for high-resolution video synthesis. For each layer, it introduces additional temporal neural network layers to learn to align individual frames in a temporally consistent manner. The spatial layers still interpret the video as a batch of independent images. During training, the spatial layers are fixed and only the temporal layers are optimized. This way, the model retains the native image generation capabilities by simply skipping the temporal blocks. The network architecture is shown below:
Figure 3. Left: VideoLDM turns a pre-trained LDM into a video generator by inserting temporal layers that learn to align frames into temporally consistent sequences. Right: During training, the base model interprets the input sequence as a batch of images. For the temporal layers, these batches are reshaped into video format. Their output \(z'\) is combined with the spatial output \(z\), using a learned merge parameter \(\alpha\).
An advantage of this training strategy is that huge image datasets can be used to pre-train the spatial layers, addressing the data availability issue to an extent. However, an issue of this strategy is that the autoencoder of the LDM is trained on images only, causing flickering artifacts when encoding and decoding a temporally coherent sequence of images. To counteract this, Video LDM introduces additional temporal layers for the autoencoder’s decoder and fine-tunes it on video data with a (patch-wise) temporal discriminator built from 3D convolutions.
Stable Video Diffusion (Blattmann et al., 2023) is an extension of Video LDM that (1) finetunes the whole model and (2) applies several data filtering techniques to improve the quality of the video dataset. They show that a filtered, higher quality dataset leads to better model quality, even when this dataset is much smaller.
That said, both Video LDM and Stable Video Diffusion still fall short of directly generating long, high FPS videos (they need a separate frame interpolation model). Why? It's still about the computational cost. While video data has a lot of temporal redundancy, these methods are still stuck encoding video frame-by-frame with an image-based VAE. They have to lean on pre-trained image VAE to keep the data availability issue in check, failing to leverage the temporal redundancy of video data.
So, how can we tackle this? What if we design an encoder that can compress images spatially and videos both spatially and temporally? To make this work, we’d also need a backbone capable of handling varying input lengths. This design would let us leverage the video data’s temporal redundancy for lower computational cost while enabling joint training on both image and video data to address data availability. This motivates the following models.
Phenaki (Villegas et al., 2022) is an innovative design that uses (1) a "causal" encoder C-ViViT that can encode both images and videos into discrete embeddings and (2) a transformer backbone to work with variable-length videos. This helps Phenaki jointly train on image and video data to address the data availability issue. The encoder performs temporal compression to help reduce computational cost. See the figure below for an illustration of each component:
Figure 4. The architecture of Phenaki. Left: Encoder architecture. The embeddings of images and video frames \(x\) are processed by a spatial and then a causal transformer (auto-regressive in time) to generate video tokens \(z\). Center: MaskGiT is trained to reconstruct masked tokens \(z\) predicted by a frozen encoder and conditioned on T5X tokens of a given prompt \(p_0\). Right: Generate arbitrary long videos by freezing the past token and generating the future tokens. The prompt can change over time to enable time-variable prompt (i.e. story) conditional generation. The subscripts represent time (i.e. frame number).
Another cool thing about Phenaki is its "story-telling capability". It can autoregressively generate videos conditioned on a sequence of text prompts that together form a story. See this video for a 9-min walkthrough of Phenaki by the authors.
W.A.L.T (Gupta et al., 2023) shares many similarities with Phenaki at a high level, including the use of a causal encoder, joint image and video training, and auto-regressive long-video generation. Different from Phenaki, it uses a continuous tokenizer and thus the latent representation is real-valued and quantization-free.
The tokenizer architecture is based on MAGVIT-v2 (Yu et al., 2023). It replaces the transformer of Phenaki's tokenizer with a 3D CNN for 2 reasons: (1) the positional embeddings of transformer makes it difficult to tokenize spatial resolutions that were not seen during training, and (2) empirically, 3D CNNs perform better than spatial transformer and produce tokens with better spatial causality of the corresponding patch. For the backbone, it replaces MaskGIT transformer with a DiT-variant that supports interleaved spatial and spatial-temporal window attention. It trains the model with the diffusion formulation. Text conditioning is integrated into the model via cross-attention layers.
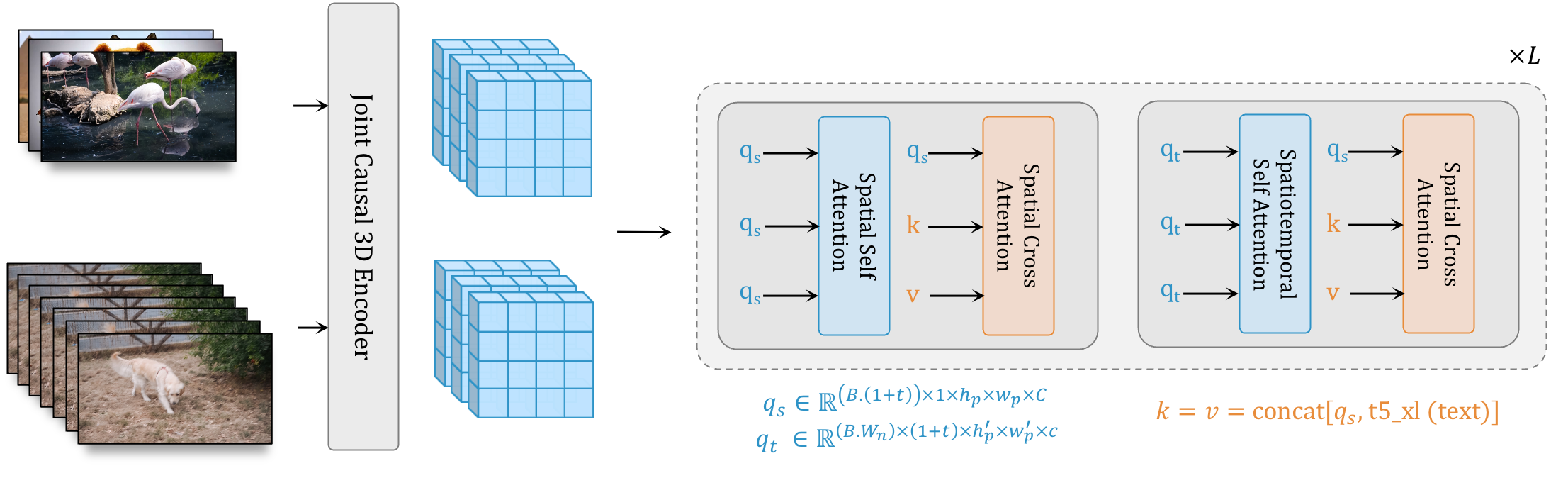
Figure 5. The interleaved spatial and spatial-temporal window attention in W.A.L.T.
With all the advancements, the general consensus was that we were still far from building production-ready video generation models. However, things changed in February 2024.
Sora (Brooks et al., 2024) is the project from OpenAI that got everyone talking. It can generate minute-long videos from an input text prompt (1):
- "A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about."
Announcing Sora — our model which creates minute-long videos from a text prompt: https://t.co/SZ3OxPnxwz pic.twitter.com/0kzXTqK9bG
— Greg Brockman (@gdb) February 15, 2024
The impressive results attracted strong interest from the research community. However, OpenAI does not release a detailed technical report of Sora. The blog post provides some insights: (1) it adopts the LDM framework (as shown in the figure below), (2) the backbone is a DiT (Peebles et al., 2023), (3) it is jointly trained on image and video data, (4) it can sample widescreen 1920x1080p videos, vertical 1080x1920 videos and everything inbetween, and (5) it leverages prompt rewriting similar to DALL·E 3.
Figure 6. Visual input (image or video) is represented as a sequence of spatio-temporal tokens for the backbone transformer.
After Sora is released, many labs started to seriously scale up the data, compute, and model size of video generation models. In the following, I will cover some of the notable open-weights and proprietary models.
Open Weights Models
CogVideoX (Yang et al., 2024) is an open-weight video model family with a 2B and a 5B model. Similar to W.A.L.T, it uses a continuous, 3D caucal convolution tokenizer and trains the model with the diffusion formulation. Different from W.A.L.T, it foregoes the interleaved spatial and temporal window attention and opts for full-attention across spatio-temporal tokens. This design decision is explained in the following figure:
Figure 7. The separated spatial and temporal attention makes it challenging to handle the large motion between adjacent frames. In this example, the head of the person in frame \(i + 1\) cannot directly attend to the head in frame \(i\). Instead, visual information can only be implicitly transmitted through other background patches. This can lead to inconsistency issues in the generated videos.
Its backbone architecture takes as input the concatenation of the video tokens and text tokens along the sequence dimension. During the forward pass, different modalities are modulated by separate AdaLN layers. We visualize the overall architecture below:
Figure 8. The input latent video \(z_{\text{vision}}\) and text embeddings \(z_{\text{text}}\) are concatenated along the sequence dimension. The concatenated embeddings are fed into a stack of "expert transformer blocks" that apply separate AdaLN modulation for \(z_{\text{vision}}\) and \(z_{\text{text}}\).
HunyuanVideo (Kong et al., 2024) is a 13B video model from Tencent. An interesting design choice in HunyuanVideo is that they propose to replace the commonly used T5 text encoder with a customized multi-modal language model for better image-text alignment in the feature space:
Figure 9. Left: Text encoder (T5) commonly used in video generation models. Right: Using multi-modal language model features for text conditioning. A bidirectional refiner is added and jointly trained with the model to improve the expressive power of the text encoder.
Its network architecture is based on SD3's MM-DiT. This design has the same motivation as CogVideoX's separate AdaLN layers for video and text. It takes it further by having different sets of weights for video and text in dual-stream DiT blocks:
Figure 10.Left: The backbone consists of both single-stream DiT blocks and dual-stream DiT blocks. The single-stream DiT block is similar to the original DiT. Right: Dual-stream DiT block uses two separate sets of weights for text and video activations since text and video activations are conceptually different. It joins the sequences of the two modalities for the attention operation, such that both representations can work in their own space yet take the other one into account.
Additionally, HunyuanVideo has detailed studies on the effect of scaling. They present scaling laws for both image generation and video generation, showcasing the scalability of their design. Overall, scaling law is still relatively under-explored in video generation models. One possible reason is that many design choices are still evolving. Another paper, Towards Precise Scaling Laws for Video Diffusion Transformers (Yin et al., 2024), points out that diffusion models training are more sensitive to hyperparameters such as batch size and learning rate compared to LLMs, which makes it harder to derive scaling laws.
Cosmos-1.0-Diffusion (NVIDIA et al., 2025) are 7B/14B models from NVIDIA (1). It adopts the training formulation from EDM (Karras et al., 2022) with a denoiser parameterization that ensures unit variance for inputs and outputs of the neural network backbone. For joint image and video training, it uses domain-specific normalization to align latent distributions by estimating statistics independently for image and video separately. Similar to W.A.L.T, but different from CogVideoX and HunyuanVideo, it leverages cross-attention to incorporate text conditioning. The overall architecture is shown below:
- Diclaimer: I am affiliated with NVIDIA and am a co-author of this paper.
Figure 11. The model processes an input video through the encoder of the Cosmos-1.0-Tokenizer-CV8x8x8 to obtain latent representations, which are subsequently perturbed with Gaussian noise. These representations are then transformed using a 3D patchification process. In the latent space, the architecture applies repeated blocks of self-attention, cross-attention (integrating input text), and feed-forward MLP layers, modulated by adaptive layer normalization (scale, shift, gate) for a given time step \(t\). The decoder of Cosmos-1.0-Tokenizer-CV8x8x8 reconstructs the final video output from the refined latent representation.
A notable part from the technical report is the details on GPU parallelism. It presents a very simple design: use fully-sharded data parallel (FSDP) to distribute GPU memory that scales with the model size and use context parallel (CP) to distribute GPU memory that scales with the training video length and resolution. The two parallelism groups are overlapped: CP group consists of GPUs within the same node connected via NVLink, while FSDP groups span across GPUs both within and across nodes, including those in the same CP group. Note that this is different from the typical "3D paralleism" used in large-scale LLMs training where parallel groups are non-overlapping. The motivations of this design include:
- During joint image and video training, CP is dynamically disabled for the image iteration to further improve the throughput.
- Avoid unnecessary communication in cross-attention as the context length of key and value is short.
- All-to-all CP such as DeepSpeed Ulysses (Jacobs et al., 2023) can reduce the communication cost as the number of GPUs increases. This is suitable for next-generation hardware like GB200 NVL72.
Proprietary Models
Movie Gen (Polyak et al., 2024) is "a cast of models" from Meta that generate multimedia, including video and audio. Not only do they demonstrate pretty impressive results on both tasks, but the technical report is also very well-written, and I highly recommend checking it out. Due to the limited space, I will highlight some key points:
- Movie Gen challenges the common belief (from Phenaki and W.A.L.T) that causality is necessary for the encoder to handle video with variable length (including image). They show that symmetrical padding works for different video lengths as long as replicate padding is used. Another detail is that its tokenizer consists of interleaved 2D and 1D operations, which is different from the 3D operations used in other video generation models' tokenizers.
- They use a internal LLaMa3-Video model to generate video captions and show that training with this data improves the generated videos' motion qualities. This is different from the common baseline that first captions the first, middle, and last frames of the video and then use another LLM to aggregate them into a single video caption.
- They highlight the necessity of human evaluation for video generation and release MovieGenBench that contains prompts and the videos generated by their model for the community to compare against.
- They found that LLaMa3-like model architecture outperforms DiT-like architecture in video generation.
- They illustrate the parallelism strategy used to scale up the model in the following figure. It makes use of multiple techniques including Tensor Parallelism and its extension that shards activations along the sequence dimension for normalization layers, Context Parallelism, and FSDP:
Figure 12. Left: Illustration of the Transformer backbone and color-code different model parallelizations used to shard the 30B model. Right: Feature dimensions in a number of key steps during the most expensive stage of Movie Gen training.
Besides text-to-video, Movie Gen also demonstrates very impressive personalization results, I will write a separate post to cover them.
Others (e.g., MiniMax, Gen3, or Veo2) do not disclose technical details so I cannot cover their methodologies here. However, that shouldn't stop us from enjoying the following video from Veo2 with stunning physical fidelity:
A physically-plausible, high-resolution video generated by Veo2."A pair of hands skillfully slicing a ripe tomato on a wooden cutting board"#veo pic.twitter.com/VDuxnkvIa0
— Agrim Gupta (@agrimgupta92) December 16, 2024
Summary
-
The common key designs of these large-scale video generation models are converging, they include (1) using continuous tokenizers without vector quantization to avoid the quality loss, (2) adopting the LDM framework to improve efficiency, (3) using DiT-based models with bidirectional attention across spatio-temporal tokens as the backbone to improve expressive power, (4) jointly training on image and video data to harness large, high-quality image datasets, and (5) employing progressive training (first expand the video length, then expand the video resolution) to save computational resources.
-
Other designs that are different among these models include: (1) whether to use causal layers in the encoder, (2) whether the training formulation is from diffusion or flow-matching perspective, (3) which text enocder to use, and (4) the exact network design to incorporate text such as cross-attention vs. dual-stream DiT. It remains an open question whether these designs will converge in the future.
Evaluation
Evaluating text-to-video or image-to-video generation is very challenging. Unlike other computer vision tasks such as object detection or image classification, text-to-video lacks a definitive ground-truth video to compare against. For any given input text prompt, multiple semantically equivalent videos can be generated, each differing in visual appearance. Classic metrics such as FVD only concerns the distribution matching between the generated video and the real videos, it does not adequately assess alignment with input text, motion quality, and temporal consistency. This raises a critical question: How to evaluate video generation models?
A practical approach is to first clarify the downstream tasks the video generation models are intended to support, and then design task-specific metrics accordingly. Below, we categorize existing evaluation benchmarks based on the tasks they aim to evaluate, grouping them into two primary categories: (1) Content Creation and (2) Data-driven Simulation.
Content Creation
VBench (Huang et al., 2024) is a popular benchmark suite that evaluates video generation models on a wide range of video generation tasks including text-to-video, image-to-video, and their trustworthiness (e.g., gender bias). For text-to-video generation, it uses 16 dimensions including subject consistency, dynamic degree, etc. For image-to-video generation, it uses 10 dimensions including video-image subject consistency, video-image background consistency, and more.
Figure 13. VBench uses carefully-curated inputs (Prompt Suite) to evalute video generation models along various dimensions (Evaluation Dimension Suite). The evaluation method for each dimension (Evaluation Method Suite) is verified with human preference.
VBench also maintains an up-to-date leaderboard that includes many latest video generation models to help the community track the progress.
EvalCrafter (Liu et al., 2023) is another text-to-video benchmark that leverages various automatic metric such as CLIP-Score, optical flow magnitude, and more to evaluate video generation quality. These metrics are combined through weighted sum to form a single score for major dimensions such as Text and Video Alignment, Motion Quality, and more. A dataset of 8647 human feedback is collected to determine the weight of each metric.
VideoScore (He et al., 2024) consists of two parts: (1) VideoFeedback: A large-scale dataset containing human-provided multiaspect score over 37.6K synthesized videos from 11 existing video generative models; (2) VideoScore: A multi-modal LLM trained on VideoFeedback to serve as a judge of generated video quality:
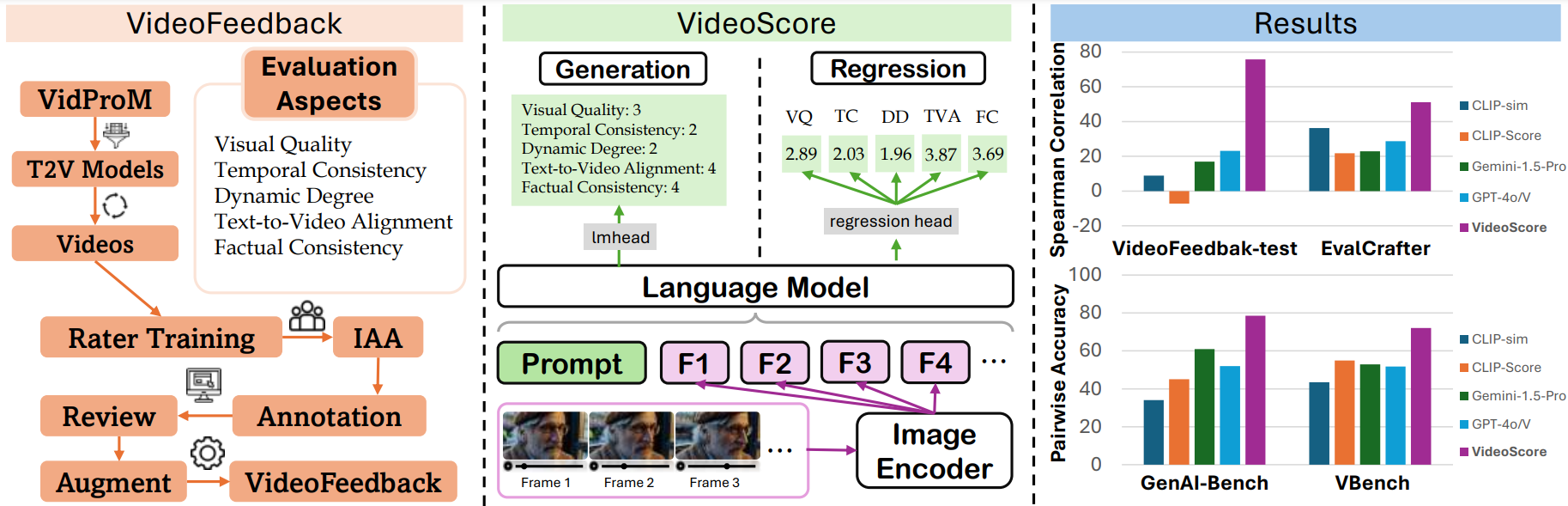
Figure 14. VideoScore is a multi-modal LLM trained on VideoFeedback to serve as a judge of generated video quality.
This paper's experiments show that the Spearman correlation between VideoScore and human feedback is higher than that of EvalCrafter and VBench. Future works along this linecan potentially simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
Data-driven Simulation
PhyGenBench (Meng et al., 2024) is a benchmark that comprises 160 carefully crafted prompts across 27 distinct physical laws, spanning four fundamental physical domains.

Figure 15. Overview of PhyGenBench. PhyGenBench comprises 160 carefully crafted prompts across 27 distinct physical laws, spanning four fundamental physical domains, which could comprehensively assesses models' understanding of physical commonsense.
The captions in PhyGenBench encompass 165 unique objects and 42 unique actions with an average length of 18.75 words, ensuring a comprehensive evaluation of a model's ability to generate physically plausible videos across different scenarios. It also proposes a novel evaluation framework called PhyGenEval that employs a hierarchical evaluation structure to assess the physical plausibility of generated videos at different levels of granularity. This hierarchical structure provides a more nuanced understanding of a model's capabilities in capturing physical realism. By assessing models' ability to generate videos that adhere to these laws, PhyGenBench provides insights into their understanding of intuitive physics and their capacity to simulate realistic scenarios.
WorldSimBench (Qin et al., 2024) is a benchmark that explicitly establishes a connection between video generation models and embodied agents. Besides the standard metrics (e.g., background consistency and instruction alignment), it also includes an interactive evaluation suite where the generated video is used as input for the video-to-action policy to follow. The predicted action is then applied in the ground-truth environment to evaluate the quality of the generated video. In WorldSimBench, the ground-truth environment could be MineRL (game), CARLA (autonomous vehicle), or CALVIN (robot manipulation).
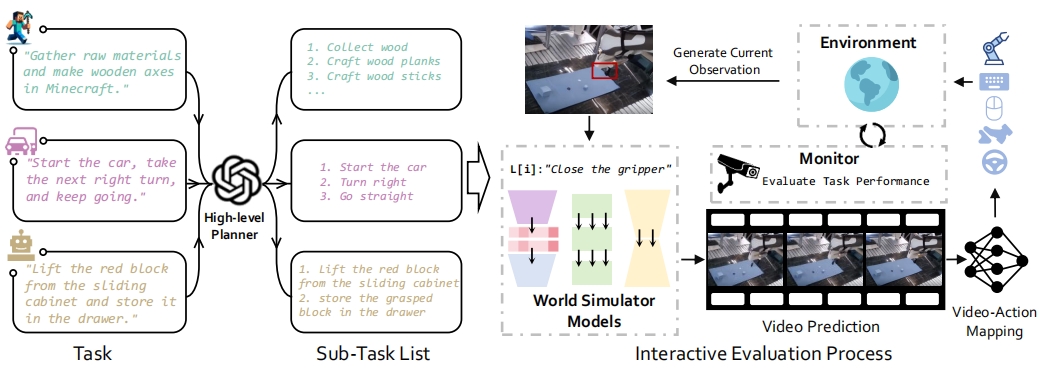
Figure 16. Embodied tasks in different scenarios are decomposed into executable sub-tasks. The video generation model generates corresponding predicted videos based on the current instructions and real-time observations. Using a pre-trained inverse dynamics model or a goal-based policy, the agent executes the generated sequence of actions. After a fixed timestep, the predicted video is refreshed by sampling again from the video generation model, and this process repeats. Finally, the success rates of various embodied tasks are obtained through monitors in the simulation environment.
Summary
Evaluations of video generation models are still in its infancy as many metrics are based on heuristics. The community is still exploring downstream applications of these models and thus it's hard to use the downstream tasks performance to help evaluation. Research along this line is highly needed and will likely be the most impactful one in the near future.
For better or worse, benchmarks shape a field.
— David Patterson
Distillation
Existing video generation models that rely on bidirectional attention are notably slow at generating videos (~5 mins). This latency makes these models unsuitable for interactive or streaming applications.
Why is sampling faster in large language models (LLMs) compared to video generation models? One reason is that LLMs use causal attention, which supports techniques like key-value caching. Also, the causal attention of LLMs enables outputs to be generated and observed incrementally by users. In contrast, video generation models with bidirectional attention process the entire sequence as a whole, delivering both the first and last frames simultaneously which delays the time for users to see the video being generated.
CausVid (Yin et al., 2024) addresses this limitation with asymmetric distillation:
- Teacher: A pretrained transformer with bidirectional attention.
- Student: A new transformer with causal attention, initialized with teacher's ODE trajectories.
This approach effectively mitigates error accumulation during autoregressive inference and allows long-duration video synthesis despite training on short clips. To further reduce latency, CausVid extends distribution matching distillation (DMD) to videos, distilling 50-step diffusion model into a 4-step generator. We visualize the procedure below:
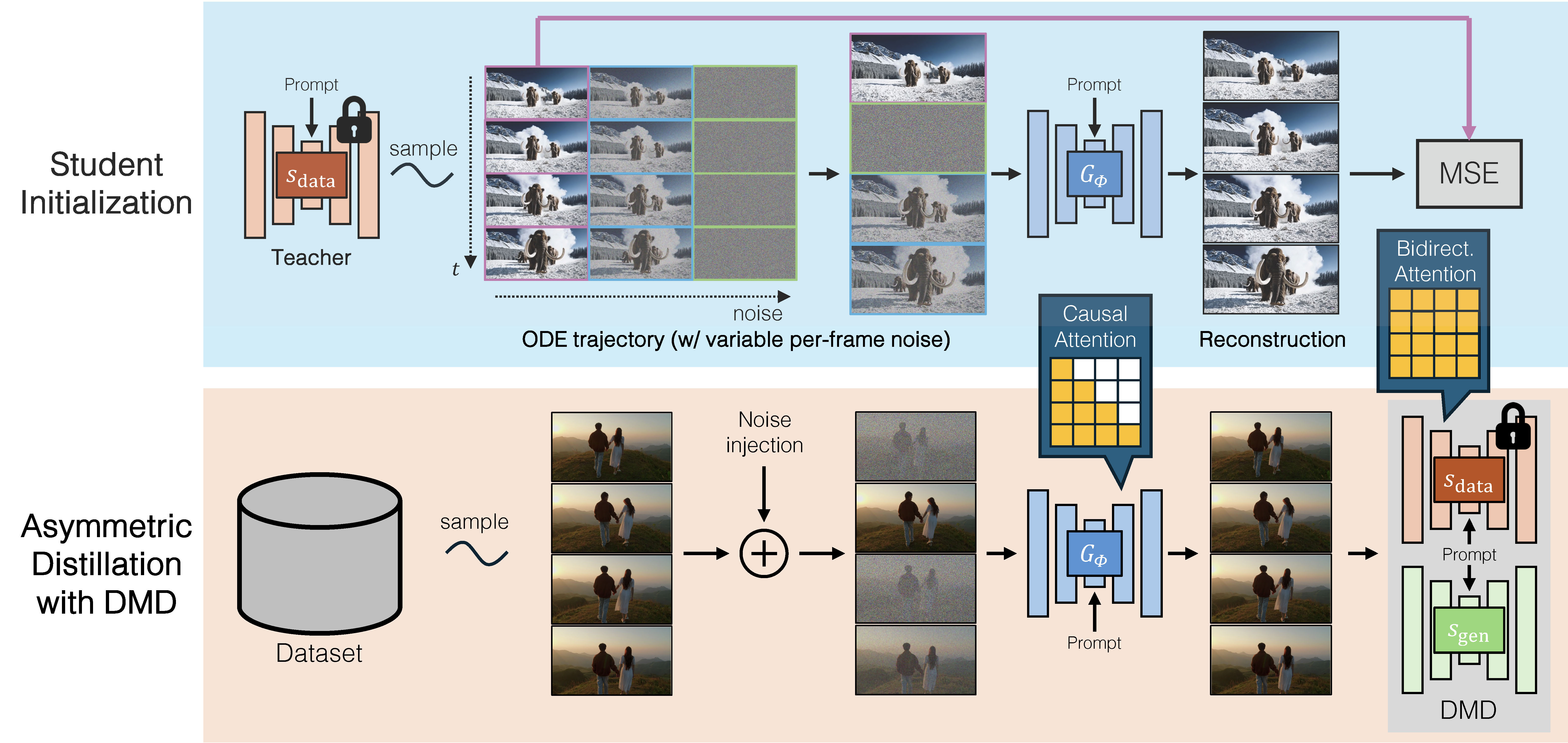
Figure 17. CausVid distills a many-step, bidirectional video diffusion model \(s_{\text{data}}\) into a 4-step, causal generator \(G_{\phi}\). The training process consists of two stages. Top: Initialize the causal student by pretraining it on a small set of ODE solution pairs generated by the bidirectional teacher. This step helps stabilize the subsequent distillation training. Bottom: Using the bidirectional teacher, CausVid trains the causal student generator through a distribution matching distillation loss (DMD).
The resulting student model supports fast streaming generation of high quality videos at 9.4 FPS on a single GPU thanks to KV caching.
CausVid, together with another paper Autoregressive Image Generation without Vector Quantization (Li et al., 2024), clarifies the design space of visual generation models. Although conventional wisdom holds that autoregressive models for visual generation are typically accompanied by vector-quantized tokens, it is not a necessity. In fact, it is possible to enjoy the speed benefits of autoregressive generation while retaining the expressiveness of continuous tokens. Another example along this line is Pandora (Xiang et al., 2024).
Note
- Qinsheng Zhang reminded me that many acceleration techniques for image generation should translate to video generation.
Libraries
xDiT (Fang et al., 2024) is an open-source project that supports multi-GPU inference of popular video generation models. Specifcially, it supports parallelizing the computation along the sequence dimension, batch dimension (for classifier-free guidance), and leveraging stale activations from the previous denoising step to speed up the generation.
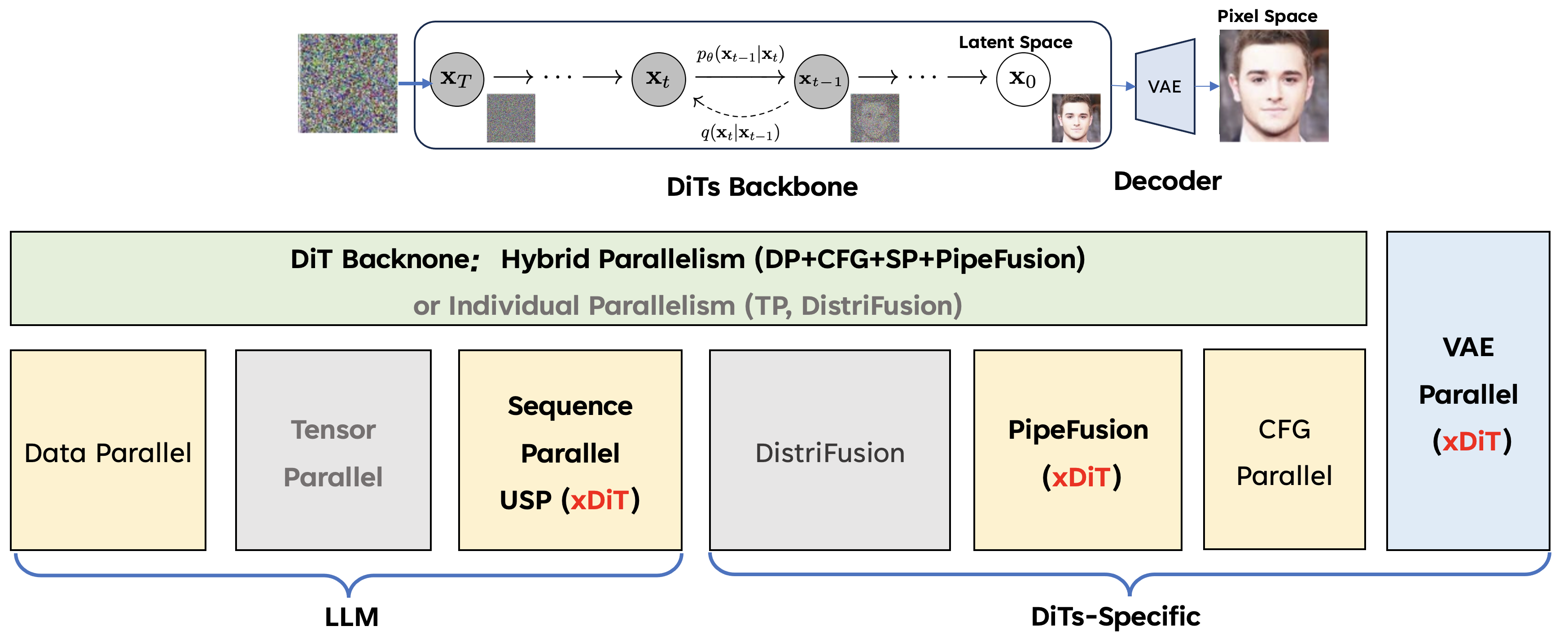
Figure 18. Overview of all parallel inference techniques in xDiT.
An interesting observation is that different from LLMs inference, it seems Tensor Parallelism is not as effective in video generation models inference due to the large activation size that induces high communication overhead. This is an interesting field to keep an eye on. I expect the community will develop performant serving engines like vLLM but for video generation models in the future.
Concluding Thoughts
In this post, we've covered many model designs evaluation benchmarks. However, I didn't cover the most important part: data. In the next post, I will discuss common data curation strategies and filtering pipeline used by state-of-the-art video generation models.
Citation
@article{yenchenlin2024video,
title = "Video Generation Models Explosion 2024",
author = "Yen-Chen, Lin",
journal = "yenchenlin.me",
year = "2025",
month = "Jan",
url = "https://yenchenlin.me/blog/2025/01/08/video-generation-models-explosion-2024/"
}
Acknowledgements
Thanks Hanzi Mao, Qinsheng Zhang, Wei-Cheng Tseng, Jinwei Gu, Chih-Yao Ma, and Ching-Yao Chuang for their valuable feedback. I also thank all the authors of these papers for their contributions to the video generation community.
References
- Rombach et al., 2022, “High-Resolution Image Synthesis with Latent Diffusion Models”
- Peebles et al., 2023, “Scalable Diffusion Models with Transformers”
- Betker et al., 2023, “Improving Image Generation with Better Captions”
- Blattmann et al., 2023, “Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models”
- Blattmann et al., 2023, “Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets”
- Villegas et al., 2022, “Phenaki: Variable Length Video Generation From Open Domain Textual Description”
- Gupta et al., 2023, “Photorealistic Video Generation with Diffusion Models”
- Brooks et al., 2024, “Sora”
- Yang et al., 2024, “CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer”
- Kong et al., 2024, “HunyuanVideo: A Systematic Framework For Large Video Generation Model”
- NVIDIA et al., 2025, “Cosmos World Foundation Model Platform for Physical AI”
- Polyak et al., 2024, “Movie Gen: A Cast of Media Foundation Models”
- Yin et al., 2024, “Towards Precise Scaling Laws for Video Diffusion Transformers”
- Meng et al., 2024, “Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation”
- Qin et al., 2024, “WorldSimBench: Towards Video Generation Models as World Simulators”
- He et al., 2024, “VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation”
- Liu et al., 2023, “EvalCrafter: Benchmarking and Evaluating Large Video Generation Models”
- Huang et al., 2024, “VBench : Comprehensive Benchmark Suite for Video Generative Models”
- Jacobs et al., 2023, “DeepSpeed Ulysses: Advanced GPU Parallelism for Diffusion Models”
- Yin et al., 2024, “From Slow Bidirectional to Fast Causal Video Generators”
- Li et al., 2024, “Autoregressive Image Generation without Vector Quantization”
- Xiang et al., 2024, “Pandora: Towards General World Model with Natural Language Actions and Video States”
- Fang et al., 2024, “xDiT”