Learning to See before Learning to Act: Visual Pre-training for Manipulation
Lin Yen-Chen1,2 Andy Zeng1 Shuran Song1,3 Phillip Isola2 Tsung-Yi Lin1
1 Google AI 2 MIT CSAIL 3 Columbia University
Paper | Blog | Video
ICRA 2020
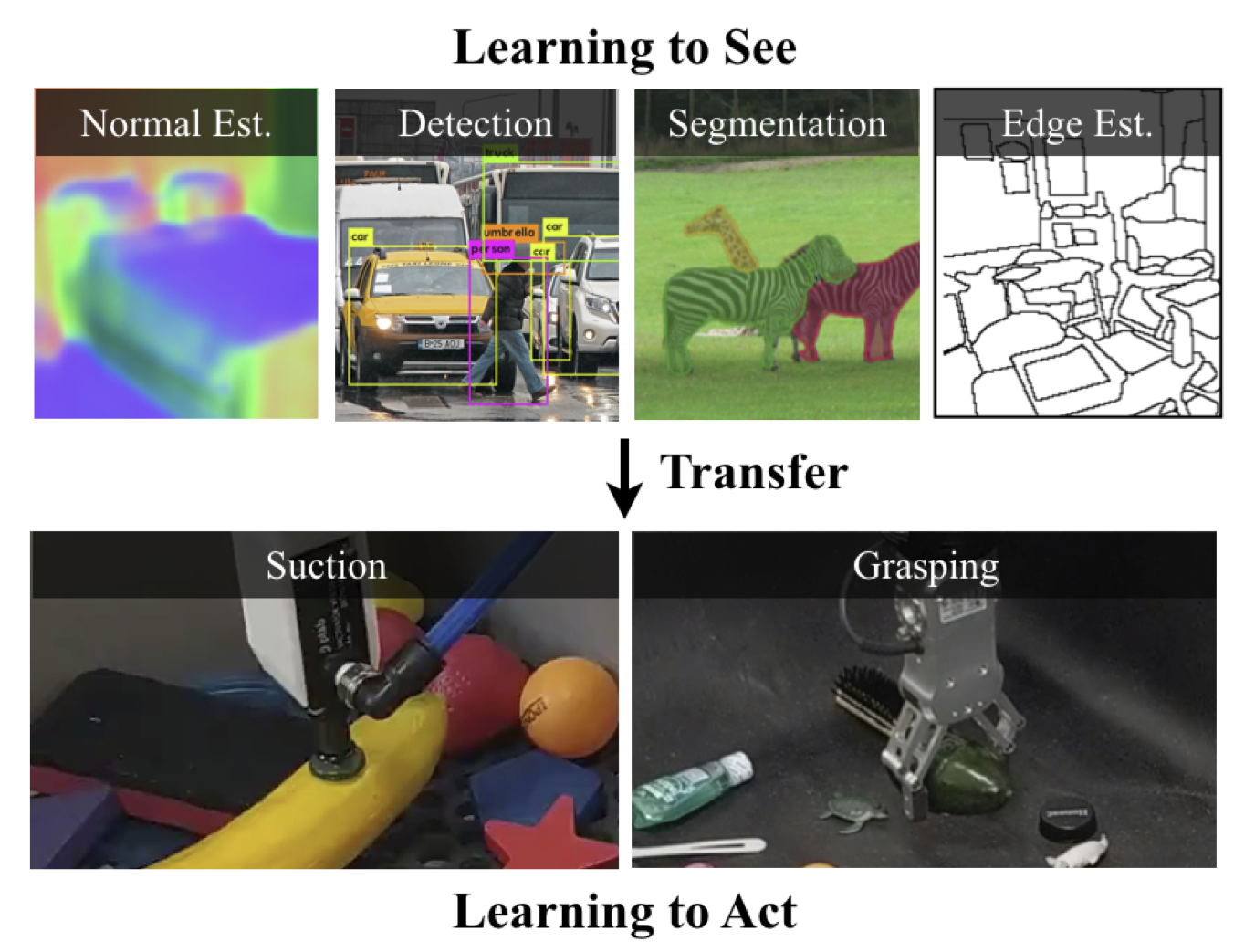
Abstract
Does having visual priors (e.g. the ability to detect objects) facilitate learning to perform vision-based manipula-tion (e.g. picking up objects)? We study this problem under the framework of transfer learning, where the model is first trained on a passive vision task, and adapted to perform an active manipulation task. We find that pre-training on vision tasks significantly improves generalization and sample efficiency for learning to manipulate objects. However, realizing these gains require scareful selection of which parts of the model to transfer. Our key insight is that outputs of standard vision models highly correlate with affordance maps commonly used in manipulation. Therefore, we explore directly transferring model parameters from vision networks to affordance prediction networks, and show that this can result in successful zero-shot adaptation, where a robot can pick up certain objects with zero robotic experience. With just a small amount of robotic experience, we can further fine-tune the affordance model to achieve better results. With just 10 minutes of suction experience or 1 hour of grasping experience, our method achieves∼80% success rate at picking up novel objects.
What Is Affordance?
In our work, we define affordance as probability of picking success. Given an RGB-D image, we predict pixel-wise affordance which represents the success rate of performing the corresponding motion primitive at that pixel’s projected 3D position. The motion primitive is then executed by the robot at the position with the highest affordance value.

How to Learn Affordance?
We can let robot measure the success of grasping automatically after each trial and train itself with self-supervised learning.

However, learning affordance leads to two problems: 1) bad sample efficiency and 2) limited generalization due to limited training objects.
How to Learn Affordance with Better Generalization and Sample Efficiency
We propose to transfer knowledge learned from static computer vision dataset to improve affordance model's generalization and sample efficiency. However, simply transferring ImageNet features doesn't speed up the learning of affordance. The key problem is that by randomly initializing the head of the affordance model, the resulting policy, even with pre-trained latent features, still randomly explores the environments and thus fails to collect useful supervisory signals. Therefore, we note that it's important to transfer the entire vision model, including both features from the backbone and the visual predictions from the head, to initialize the affordance model. In this case, the resulting initial policy is simply the pre-trained vision model. We show that such vision-guided exploration greatly reduces the number of interactions needed to acquire a new manipulation skill and lead to better generalization.
Play the following video for illustration:
Results
Generalization with or without Visual Pre-training

Ours (visual pre-training):
|

Baseline (random initialization):
|
More Results with Visual Pre-training
Grasping Transparent Objects
|

Grasping Unseen Objects
|

Grasping Seen Objects
|
Analysis
We show the affordances of suction predicted by different models given input from (a). (b) Random refers to a randomly initialized model. (c) ImageNet is a model with backbone pre-trained on ImageNet and randomly initialized head. (d) Normal refers to a model pre-trained to detect pixels with normal close to anti-gravity axis. (e) COCO is the modified RPN model. (f) Suction is a converged model learned from robot-environment interactions.


Paper
Citation
Lin Yen-Chen, Andy Zeng, Shuran Song, Phillip Isola, and Tsung-Yi Lin. "Learning to See before Learning to Act: Visual Pre-training for Manipulation", ICRA 2020. Bibtex
Video
Related Work
Acknowledgement
We thank Kevin Zakka and Jimmy Wu for all the good meals together.
